Abstract
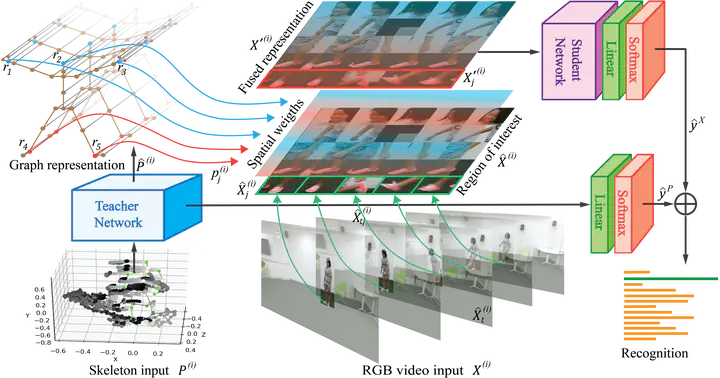
Indoor action recognition plays an important role in modern society, such as intelligent healthcare in large mobile cabin hospitals. With the wide usage of depth sensors like Kinect, multimodal information including skeleton and RGB modalities brings a promising way to improve the performance. However, existing methods are either focusing on a single data modality or failed to take the advantage of multiple data modalities. In this paper, we propose a Teacher-Student Multimodal Fusion (TSMF) model1 that fuses the skeleton and RGB modalities at the model level for indoor action recognition. In our TSMF, we utilize a teacher network to transfer the structural knowledge of the skeleton modality to a student network for the RGB modality. With extensive experiments on two benchmarking datasets: NTU RGB+D and PKU-MMD, results show that the proposed TSMF consistently performs better than state-of-the-art single modal and multimodal methods. It also indicates that our TSMF could not only improve the accuracy of the student network but also significantly improve the ensemble accuracy.
Bruce X.B. Yu
Assistant Professor
My research interests include distributed robotics, mobile computing and programmable matter.